图结构
1 图的基本概念
- 图结构是一种非常常见的数据结构
- 图
- 图结构是一种与树结构有些相似的数据结构
- 树是图的一种
- 以图为研究对象,以顶点和边组成的图形的数学理论和方法
- 主要研究的目的是:事务之间的关系,顶点表示事物,边表示关系
- 图的现实案例
- 人与人之间的关系网
- 图的特点
- 度:
- 一个顶点的度时相邻顶点的数量
- 路径:顶点v1,v2…vn的一个连续序列
- 简单路径:要求不包含重复的顶点
- 回路:第一个顶点和最后一个顶点相同的路径
- 简单路径:要求不包含重复的顶点
- 无向图:所有的边都没有方向
- 有向图:图中的边都是有方向的
- 无权图:图的边是没有权重的
- 有权图:图的边是有权重的,权重可以是任意你想表示的数字
2 图的表示
- 顶点抽象成ABCD,分别用数组进行存储
- 图的表示:
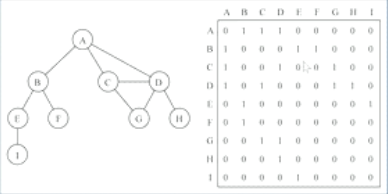
- 邻接矩阵让每个节点和一个整数相关联,该整数作为数组的下标值
- 用二维数组来表示顶点之间的连接:[0][2]->A->C
- 图片解析
- 在二维数组中,0表示没有连线,1表示有连线
- 通过二维数组,可以很快找到一个顶点和哪些顶点有连线
- 顶点自己到自己的连线通常0表示
- 图片解析
- 领接矩阵的问题
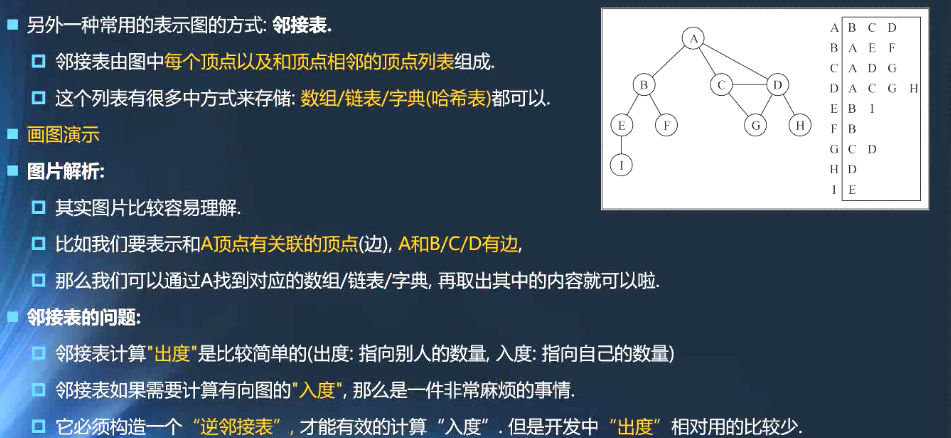
- 邻接表由每个顶点以及点点列表组成
- 顶点列表可以是数组/链表.字典/哈希表
- 问题:计算入度方便,计算出度比较麻烦,可以使用逆邻接表的方式
2.3 图结构的封装
- 这里采用邻接表进行封装,边集合:字典,顶点集合:数组,字典里顶点列表:数组,存储的是无向图
1
2
3
4
5function Graph() {
// 封装属性
this.vertexes = [];//顶点集合
this.adjList = new Dictionay();//通过字典来存储边
} - 图的方法:
- 添加方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28// 1.添加顶点,边,toString方法
Graph.prototype.addVertex = function (v) {
this.vertexes.push(v);
// 添加边的顶点列表为一个空的数组
this.adjList.set(v, []);
}
// 2.添加边
Graph.prototype.addEdge = function (v1, v2) {
// 这是是无向图的实现
this.adjList.get(v1).push(v2);
this.adjList.get(v2).push(v1);
}
// 3.toString方法
/*
先获取所有的节点,在把节点中的顶点列表打印出来
*/
Graph.prototype.toString = function () {
var resultStr = ""
for (var i = 0; i < this.vertexes.length; i++) {
resultStr += this.vertexes[i] + "->"
var adj = this.adjList.get(this.vertexes[i])
for (var j = 0; j < adj.length; j++) {
resultStr += adj[j] + " "
}
resultStr += "\n"
}
return resultStr
}
- 添加方法:
2.4 图结构的遍历
- 图的遍历和树的遍历思想是一样的
- 图的遍历意味着要将图中的每个顶点访问一遍,且不能有重复的访问
- 有两种算法可以对图进行遍历
- 广度优先搜索(Breadth-First Search,简称BFS)
- 深度优先搜索(Depth-First-Search,简称DFS)
这两种遍历算法都需要明确指定第一个被访问的节点
- 通过三种颜色来反应他们的状态
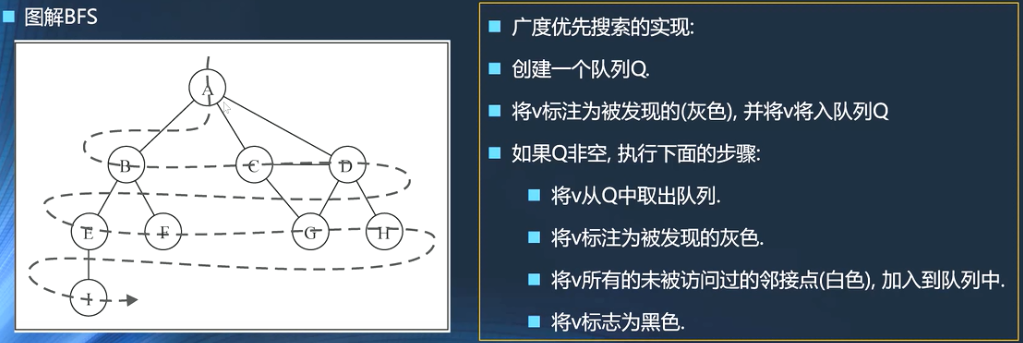
- BFS:基于队列,先入队列的顶点先被访问
- 广度优先搜索会从指定的第一个节点开始访问,先访问其所有的相邻节点,就像一次访问图的一层
- 也就是先宽后深的访问顶点
- BFS图解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36// 4.BFS搜索遍历的实现
/*
v:访问的初始节点
callback:回调函数,处理节点
*/
Graph.prototype.BFS = function (v, callback) {
// (1)初始化顶点
var colors = this.initializeColor();
// (2)创建队列
var queue = new Queue();
// (3)将传入的初始节点放入队列中
queue.enqueue(v);
// (4)从队列依次取出和放入数据
while (!queue.isEmpty()) {
// 从队列中取出数据
var qv = queue.dequeue();
// 获取qv相邻的所有顶点
var vAdj = this.adjList.get(qv);
// 将qv的颜色设置为灰色
colors[qv] = 'gray';
// 将qv的所有领接顶点放入队列
for (var i = 0; i < vAdj.length; i++) {
var e = vAdj[i];
if (colors[e] == 'white') {
colors[e] = 'gray';
queue.enqueue(e);
}
}
// qv探测完毕,设置为黑色
colors[qv] = 'black';
// 处理qv
if (callback) {
callback(qv);
}
}
}2.4.2 广度优先算法(DFS)
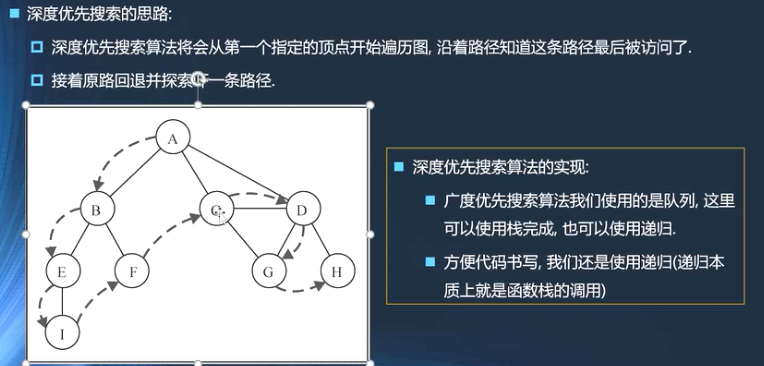
- DFS:基于栈或使用递归,通过将顶点存入栈中,顶点沿着路径被探索到,存在新的相邻顶点就去访问,当前节点访问结束在回退
- 这里采用递归的方式进行访问
- 和树的先序遍历很像
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31Graph.prototype.DFS = function (v, callback) {
// 初始化节点颜色
var colors = this.initializeColor();
// 遍历所有节点进行访问
for (var i = 0; i < this.vertexes.length; i++) {
if (colors[this.vertexes[i]] == 'white') {
// 递归调用
this.dfsVisit(this.vertexes[i], colors, callback);
}
}
}
//dfs递归调用方法处理当前节点
Graph.prototype.dfsVisit = function (u, color, callback) {
// 当前访问的顶点变为灰色
color[u] = 'gray';
// 处理u顶点
if (callback) {
callback(u);
}
// u所有邻接顶点的访问
var uAdj = this.adjList.get(u);
for (var i = 0; i < uAdj.length; i++) {
var w = uAdj[i];
if (color[w] == 'white') {
this.dfsVisit(w, color, callback);
}
}
// 当前节点处理结束设置为黑色
color[u] = 'black';
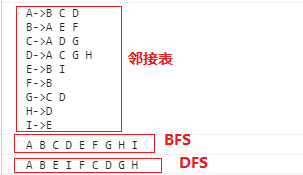
} - 执行结果
本文作者:
SparkParis
本文链接: https://sparkparis.github.io/2020/04/17/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%844/
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!
本文链接: https://sparkparis.github.io/2020/04/17/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%844/
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!

