哈希表
1哈希:
散列(hashing)是电脑科学中一种对资料的处理方法,通过某种特定的函数/算法(称为散列函数/算法)将要检索的项与用来检索的索引(称为散列,或者散列值)关联起来,生成一种便于搜索的数据结构(称为散列表),也叫哈希
2 哈希函数
哈希函数具有的基本特性:根据同一散列函数,如果两个散列值是不相同的,那么这两个散列值的的原始输入也是不相同的。这个特性是散列函数具有确定性的结果,具有这种性质的散列函数称为单行散列函数
通过哈希函数可以获取HashCode
3 哈希表
js中的对象是基于哈希表结构的,而哈希表的查找时间复杂度为O(1),所以很多人喜欢用对象来做映射,减少遍历循环
3.1 哈希表的介绍
若关键字为k,则值存放在f(k)的存储位置上,不需比较便可直接取得所得所查记录,称这个对应关系f为散列函数,按这个思想简历起来的表为散列表
对不同的关键字可能得到同一散列值。即k1不等于k2,f(k1)=f(k2),这种现象称为冲突,对于相同函数值的关键字对该散列函数来说称为同义词
解决冲突:根据散列函数f(k)和处理冲突的方法将一组关键字映射到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“像”作为记录在表中的存储位置,这种表便称为散列表,这一映射过程称为散列造表或散列,所得的存储位置称散列地址。
均匀散列函数(Uniform Hash function):若对于关键集合中的任一关键字,经散列函数映射到地址集合中任何一个地址的概率是相等的,则称为均匀散列函数,关键字经过散列函数得到一个’随机的地址’,从而减少冲突
3.2 字母转数字
方案
出现的问题:
冲突不可避免,必须解决冲突
解决方案:
每个下标值存储的不在是一个数字而是一个数组或者一个链表

(2)开放地址法(寻找空白单元格)
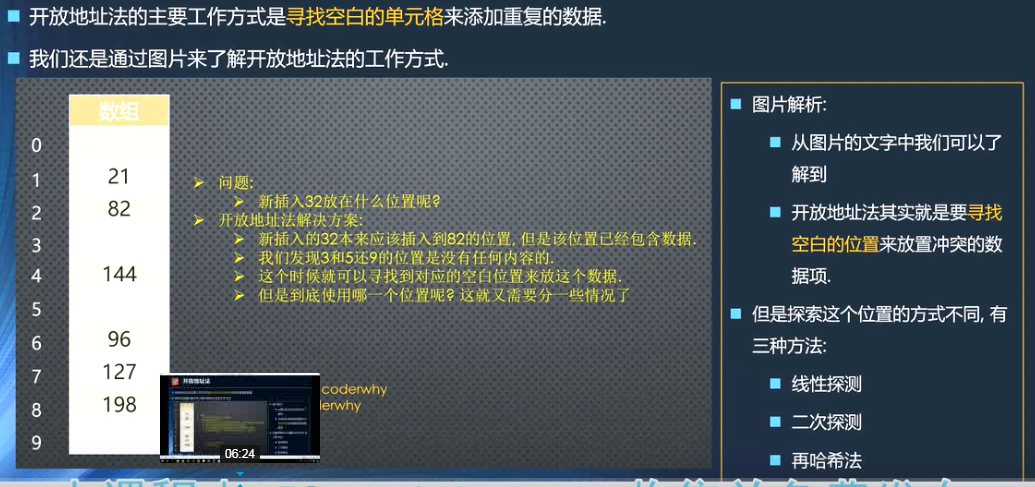
开放地址法中寻找位置的三种方式
- 线性探测
- 二次探测
- 再哈希法
线性探测
- 线性探测注意事项
- 1.删除数据项时,不能将这个位置下标内容设置为null,会影响之后的查询的其他操作,通常删除一个位置的数据项时,将它的下标进行特殊处理(比如设置为-1)
- 线性探测的问题:
- 会出现比较严重的聚集问题(一连串填充单元叫做聚集)
- 之前插入的数据如果是连续的,之后的探测可能会探测很长时间
- 聚集会影响哈希表的性能(连续的单位可能都不允许我们放置数据)
- 解决:二次探测可以解决一部分的问题
- 线性探测注意事项
二次探测
- 二次探测主要对步长做了优化,可以一次性探测比较长的距离,避免聚集带来的影响(线性探测的补步长是1)
- 问题:
- 会出现步长不一的聚集,还是会影响效率
- 解决:哈希法
才能彻底解决聚集问题
再哈希法(采用两个不同的哈希函数,一个用于计算步长,一个用于计算下标值)
- 再哈希化
- 产生一种依赖于关键字的探测序列,而不是每个关键字都一样
- 不同的关键字即使映射到相同的数组下标,也可以使用不同的探测序列
- 在哈希化的做法: 把关键字用另外的哈希函数再做一次哈希化,将这一次的结果作为步长
- 对于指定的关键字,步长在整个探测中是不变的,不过不同的关键字使用不同的步长
- 再哈希化的特点:
- 和第一个哈希函数不同
- 不能输出为0
- 常用的再哈希化的哈希函数
1
2
3
4stepSize = constant - (key%constant)
ps:
- constant:是质数,且小于数组的容量
eg: stepSize = 5-(key%5);
- 哈希化的效率
- 哈希化中执行和搜索操作效率是非常高的
- 没有冲突,效率会更高
- 发生冲突,存取时间依赖于后来的探测长度
- 平均探测长度以及平均存取时间,取决于装填因子
- 装填因子变大,效率下降
- 哈希化中执行和搜索操作效率是非常高的
- 装填因子
- 再哈希化
哈希函数设置:
- 哈希函数中尽量减少有乘法和除法.他们的性能比较低
- 哈希表的主要优点在于他的速度
好的哈希函数应该具备的特点
- 快速的计算(快速获取到hashCode):这里采用秦九韶算法(霍纳法则)

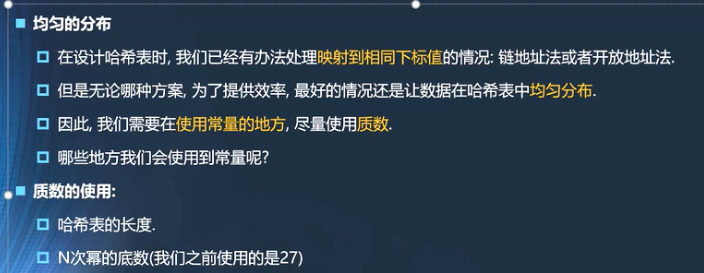
- 均匀的分布(哈希表的长度最好使用质数)
- 快速的计算(快速获取到hashCode):这里采用秦九韶算法(霍纳法则)
哈希表的长度中采用质数在开放地址法中非常中要,在java中不是那么重要

哈希在开放地址法中采用的是模运算
扩展:
- java中的哈希表采用的是链地址法
- HashMap的初始长度是16,每次自动扩充,长度必须是2的次幂
- 这里为了服务从key映射到index的算法6000%100=数字.下标
- HashMap中为了提高效率采用的是位运算

详细的hash介绍见(https://juejin.im/entry/5a249d5d5188257bfe45ab6c)
哈希函数的创建
- 将字符串转化为较大的数字:HashCode
- 较大的数字HashCode压缩到数组范围
- 一般来讲,越是质数,mod取余就越可能分布的均匀。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22/*
将字符串映射到大的数字,较大的数字压缩到数组范围
- str:字符串
- size:数组大小:取质数
*/
function hashFunc(str, size) {
//1. 初始化hashCode
hashCode = 0;
// 霍纳法则计算hashCode
for (var i = 0; i < str.length; i++) {
// 这里的37就是秦九韶算法中的x,一般取质数
hashCode = 37 * hashCode + str.charCodeAt(i);//charCodeAt()获取字符编码值
}
// 取模运算
hashCode = hashCode % size;
return hashCode;
}
// 测试
console.log(hashFunc('abs', 7));
console.log(hashFunc('ads', 7));
console.log(hashFunc('ebs', 7));
console.log(hashFunc('ats', 7));3.6 哈希表
哈希表设计
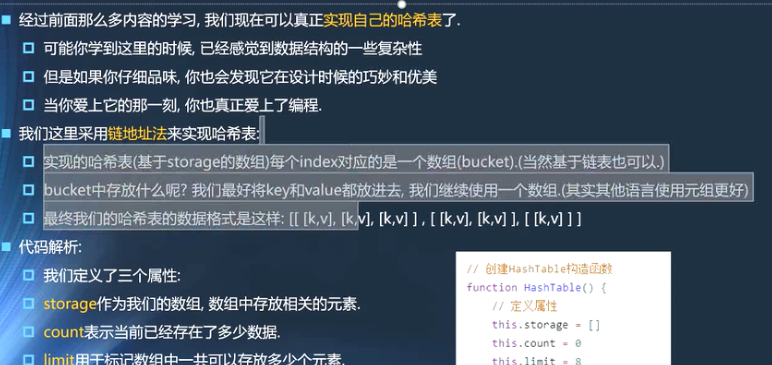
哈希表结构
哈希表封装
1
2
3
4
5
6
7function HashTable() {
// 定义属性
this.storage = [];
this.count = 0;//计算加载因子loadFactor:>0.75进行扩充,<0.25时是有很多空余
this.limit = 8;//标记数组汇总存放的元素
// 封装方法
}哈希表方法
- 哈希表的插入和修改
- 根据key获取索引值:将数据插入到对应的位置
- 根据索引值取出bucket
- 如果桶不存在则创建,并且在桶中放置
- 判断新增还是修改
- 已经有值进行修改
- 反之进行插入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31HashTable.prototype.put = function (key, value) {
// (1)获取对应的索引值
var index = this.hashFunc(key, this.limit);
// (2)取出数组(也可以使用链表)
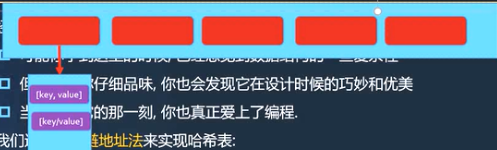
// 数组中放置数据的方式: [[ [k,v], [k,v], [k,v] ] , [ [k,v], [k,v] ] [ [k,v] ] ]
var bucket = this.storage[index];
// (3)判断数组是否存在
if (bucket == null) {
// 创建新的数组并放入
var bucket = [];
this.storage[index] = bucket;
}
//(4)判断是新增还是修改
for (var i = 0; i < bucket.length; i++) {
var tuple = bucket[i];
if (tuple[0] === key) {
tuple[1] = value;
return;
}
}
// (5)不是修改则进行添加
bucket.push([key, value]);
this.count++;
// 插入的填充因子>0.75进行扩容
if (this.count > this.limit * 0.75) {
<!-- 寻找最近的质数 -->
var newsize = this.getPrime(this.limit * 2);
this.resize();
}
}
- 获取方法
- 根据key获取对应的index
- 根据index获取对应的bucket
- 判断bucket是否为空
- 为空:则返回null
- 线性查找bucket中每个key是否等于传入的key
- 等于直接返回对应的value
- 遍历结束后依然没有找到直接return null;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16HashTable.prototype.get = function (key) {
var index = this.hashFunc(key, this.limit);
var bucket = this.storage[index];
if (bucket == null) {
return null;
}
// 遍历
for (var i = 0; i < bucket.length; i++) {
var tuple = bucket[i];
if (tuple[0] == key) {
return tuple[1];
}
}
// 遍历结束没有找到
return null;
}
- 删除操作
- 根据key获取对应的index
- 根据index获取对应的bucket
- 判断bucket是否为空
- 为空:则返回null
- 线性查找bucket中每个key是否等于传入的key
- 等于直接删除并返回对应的value
- 遍历结束后依然没有找到直接return null;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24HashTable.prototype.remove = function (key) {
var index = this.hashFunc(key, this.limit);
var bucket = this.storage[index];
if (bucket == null) {
return null;
}
// 遍历
for (var i = 0; i < bucket.length; i++) {
var tuple = bucket[i];
if (tuple[0] == key) {
// 删除,数组中删除采用splice
bucket.splice(i, 1);
this.count--;
// 删除的小于limit时缩容
if (this.count < 7 && this.count < this.limit * 0.25) {
<!-- 寻找最近的质数 -->
var newsize = this.getPrime(Math.floor(this.limit / 2));
this.resize(newsize);
}
return tuple[1];
}
}
- 哈希表的插入和修改

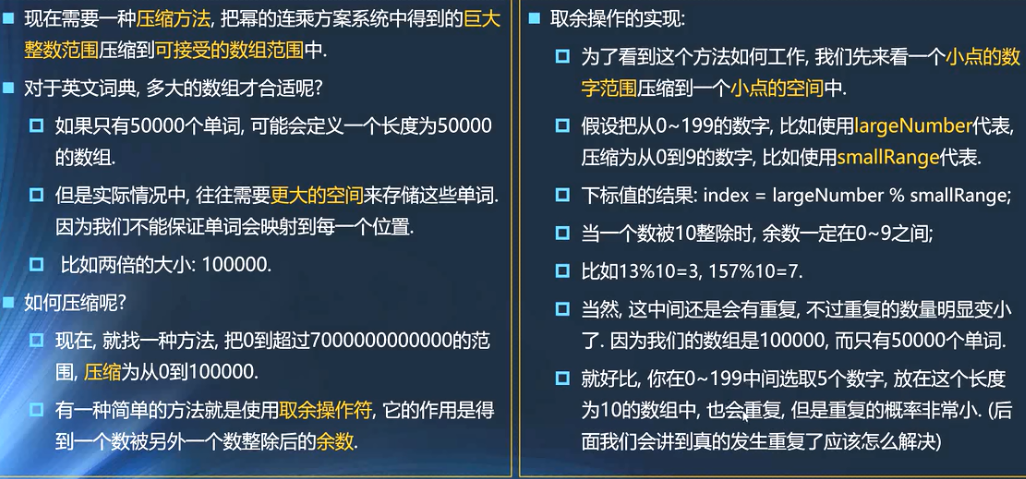

3.7 哈希表的扩容
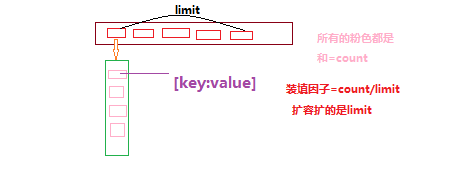
- 为什么需要扩容
- 所有的数组放在limit=7的数组总
- 使用的是链地址法,loadFactor可以大于1,所以这个哈希表可以无限制的插入新数据
- 随着数据量的增多,每一个index对应的数据量会无限制的增多,造成效率降低
- 在合适的情况下对数组进行扩容,比如扩容两倍
- 如何进行扩容
- 扩容可以简单的将容量扩充两倍(不是质数的问题可以在后面讨论)
- 扩容之后,所有的数据项一定要同时进行修改(重新调用哈希函数,获取到不同的位置)
- 这是一个耗时的过程,这个过程是必须的
- 扩容情况
- 填充因子>0.75的时候进行扩容
- java在中是装填因子大于0.75的时候进行扩容
- 缩容的情况:填充因子<0.25
- 代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29HashTable.prototype.resize = function (newlimit) {
// (1)保存旧的数组内容
var oldStorage = this.storage;
// (2).重置属性
this.limit = newlimit;
this.count = 0;
this.storage = [];
// 重新遍历旧数组中的所有数据项,并且插入到哈希表中
oldStorage.forEach(bucket => {
// bucket为null
if (bucket == null) {
return;//跳过当前循环,在foreach中return不会直接跳出循环
}
// 存在数据
for (var i = 0; i < bucket.length; i++) {
var tuple = bucket[i];
this.put(tuple[0], tuple[1]);
}
}).bind(this);
}
- 在插入操作结束判断是否扩容
if (this.count > this.limit * 0.75) {
this.resize(this.limit * 2);
}
- 在删除操作结束判断是否缩容
/ 删除的小于limit时缩容
if (this.count < 7 && this.count < this.limit * 0.25) {
this.resize(Math.floor(this.limit / 2));
}3.8 哈希表的容量质数
- 在哈希表扩容中尽量使用质数
- 可以在对数字进行扩容之后通过寻找最近的质数作为扩容的长度
- 哈希表中的是实现:分别插入到put方法和remove方法中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 9.获取最近的质数
HashTable.prototype.getPrime = function (num) {
while (!isPrime(num)) {
num++;
}
return num;
}
// 8.判断是不是质数
HashTable.prototype.isPrime = function (number) {
for (var i = 2; i < parseInt(Math.sqrt(number)); i++) {
if (number % i == 0) {
return false;
}
}
return true;
}
- 质数:大于1的,只能被自己和1整除的数.也叫素数
- 判断质数的实现
- 开平方根(效率快一倍)
- 直接遍历
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// 效率不高
function isPrime(number) {
for (var i = 2; i < number; i++) {
if (number % i == 0) {
return false;
}
}
return true;
}
// 采用平方根的方式
function isPrime(number) {
for (var i = 2; i < parseInt(Math.sqrt(number)); i++) {
if (number % i == 0) {
return false;
}
}
return true;
}
alert(isPrime(22))
alert(isPrime(2))
alert(isPrime(23))
alert(isPrime(24))总结:
- 哈希算法(散列算法)
- 除法散列法
1
index = key % 16,本文实现就是
- 平方散列法
- 求index是非常频繁的操作,而乘法的运算要比除法来得省时(对现在的CPU来说,估计我们感觉不出来),所以我们考虑把除法换成乘法和一个位移操作。公式:
1
index = (key * key) >> 28
- 如果数值分配比较均匀的话这种方法能得到不错的结果,另外key如果很大,key * key会发生溢出。但我们这个乘法不关心溢出,因为我们根本不是为了获取相乘结果,而是为了获取index。
- 求index是非常频繁的操作,而乘法的运算要比除法来得省时(对现在的CPU来说,估计我们感觉不出来),所以我们考虑把除法换成乘法和一个位移操作。公式:
- 斐波那契(Fibonacci)散列法
- 黄金分割法则:斐波那契数
1
2
3
4
5
6
7
8平方散列法的缺点是显而易见的,所以我们能不能找出一个理想的乘数,而不是拿value本身当作乘数呢?答案是肯定的。
- 对于16位整数而言,这个乘数是40503
- 对于32位整数而言,这个乘数是2654435769
- 对于64位整数而言,这个乘数是11400714819323198485
- 这几个“理想乘数”是如何得出来的呢?这跟一个法则有关,叫黄金分割法则,而描述黄金分割法则的最经典表达式无疑就是著名的斐波那契数列,即如此形式的序列:0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144,233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946,…。
对我们常见的32位整数而言,公式:
index = (key* 2654435769) >> 28
- 黄金分割法则:斐波那契数
- 除法散列法
- 解决冲突策略
- 拉链法变种
- 由于链表的查找需要遍历,如果我们将链表换成树或者哈希表结构,那么就能大幅提高冲突元素的查找效率。不过这样做则会加大哈希表构造的复杂度,也就是构建哈希表时的效率会变差。
- 开放寻址
- 当关键字key的哈希地址p=H(key)出现冲突时,以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2,…,直到找出一个不冲突的哈希地址pi,将相应元素存入其中。这种方法有一个通用的函数形式:根据di的不同,又可以分为线性的、平方的、随机数之类的
1
Hi=(H(key)+di)% m i=1,2,…,n
- 开发寻址的好处:是存储空间更加紧凑,利用率高。但是这种方式让冲突元素之间产生了联系,在删除元素的时候,不能直接删除,否则就打乱了冲突元素的寻址链。
- 当关键字key的哈希地址p=H(key)出现冲突时,以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2,…,直到找出一个不冲突的哈希地址pi,将相应元素存入其中。这种方法有一个通用的函数形式:
- 在哈希法
- 这种方法会预先定义一组哈希算法,发生冲突的时候,调用下一个哈希算法计算一直计算到不发生冲突的时候则插入元素,这种方法跟开放寻址的方法优缺点类似。函数表达式
1
index=Hi(key) , i=1,2,…,n
- 这种方法会预先定义一组哈希算法,发生冲突的时候,调用下一个哈希算法计算一直计算到不发生冲突的时候则插入元素,这种方法跟开放寻址的方法优缺点类似。函数表达式
- 拉链法变种
- 删除数组或者对象中的值可以采用delete,在数组中也可以采用splice()进行删除
- 哈希,字典和集合存储的都是无序的,不允许重复的
- js中的对象本身就是哈希表的结构
- Set可以是数组也可以是对象
- 字典可以是对象也可以是数组
- 哈希表
本文链接: https://sparkparis.github.io/2020/04/13/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%842/
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!

